
Manual Pages
The following are a selection of the manual pages distributed with the habitat package, considered pertinent to the User Guide.
clockwork
NAME
clockwork - collection daemon for the Habitat suite
SYNTAX
clockwork [-c <purl>] [-C <cfcmd>] [-e <fmt>] [-dDhsv] [-j <jobs>]
DESCRIPTION
Clockwork is the local agent for the Habitat suite. It runs as a dae-
mon process on each machine to be monitored and is designed to carry
out data collection, log file monitoring, data-driven actions and the
distribution of collected data.
The default jobs are to collect system, network, storage and uptime
statistics on the local machine and make them available in a standard
place. The collection of process data and file monitoring is available
by configuring the jobs that drive clockwork. Configuration can be
carried out at a local, regional and global level to allow deligation.
One public and many private instances of clockwork can exist on a sin-
gle machine, allowing individual users to carry out custom data collec-
tion Data is normally held in ring buffers or queues on the local
machine using custom datastores to be self contained and scalable.
Periodic replication of data rings to a repository is used for archiv-
ing and may be done in reverse for central data transmission.
OPTIONS
-c <purl>
Append user configuration data from the route <purl>, rather
than the default file ~/.habrc.
-C <cfcmd>
Append a list of configuration directives from <cfcmd>, sepa-
rated by semicolons.
-d Place clockwork in diagnostic mode, giving an additional level
of logging and sending the text to stderr rather than the
default or configured destinations. In daemon mode, will send
output to the controlling terminal.
-D Place clockwork in debug mode. As -d above but generating a
great deal more information, designed to be used in conjunction
with the source code. Also overrides normal outputs and will
send the text to stderr. In daemon mode, will send output to
the controlling terminal.
-e <fmt>
Change the logging output to one of eight preset alternative
formats, some showing additional information. <fmt> must be
0-7. See LOGGING below.
-h Print a help message to stdout and exit
-v Print the version to stdout and exit
-j <jobs>
Override public job table with a private one provided by the
route <jobs>. Clockwork will not daemonise, run a data service
or take an exclusive system lock (there can only be one public
clockwork instance). Implies -s and alters the logging output
to stderr, unless overridden with the range of elog configura-
tion directives.
-s Disable the public data service from being run, but will con-
tinue to save data as dictated by configuration.
DEFAULTS
When clockwork starts it reads $HAB/etc/habitat.conf and ~/.habrc for
configuration data (see CONFIGURATION for more details). Unless
overridden, clockwork will then look for its jobs inside the default
public datastore for that machine, held in $HAB/var/<hostname>.rs (the
route address is rs:$HAB/var/<hostname>.rs,jobs,0, see below for an
explanation). If it does not find the jobs, clockwork bootstaps itself
by copying a default job template from the file $HAB/lib/clockwork.jobs
into the public datastore and then carries on using the datastore ver-
sion.
The default jobs run system, network and storage data gathering probes
every 60 seconds. It saves results to the public datastore using the
template route rs:$HAB/var/<hostname>.rs,<jobname>,60 and errors to
rs:$HAB/var/<hostname>.rs,err_<jobname>,60
All other errors are placed in rs:$HAB/var/<hostname>.rs,log,0
ROUTES
To move data around in clockwork, an enhanced URL is used as a form of
addressing and is called a 'route' (also known as a pseudo-url or p-url
in documentation). The format is <driver>:<address>, where driver must
be one of the following:-
file: fileov:
reads and write to paths on the filesystem. The format is
file:<file path>, which will always append text to the file when
writing. The fileov: driver will overwrite text when first
writing and is suitable for configuration files or states.
http: https:
reads and writes using HTTP or HTTPS to a network address. The
address is the server name and object name as a normal URL con-
vention.
rs: read and writes to a ring store, the primary local storage mech-
anism. Tabular data is stored in a time series in a queue or
ring buffer structure. Multiple rings of data can be stored in
a single ringstore file, using different names and durations.
sqlrs: reads and writes tabular data to a remote repository service
using the SQL Ringstore method, which is implemented over the
HTTP protocol. Harvest provides repository services. Stores
tabular data in a time series, addressed by host name, ring name
and duration. Data is stored in a queue or ring buffer storage.
CONFIGURATION
By default, clockwork will collect system, network and storage statis-
tics for the system on which it runs. All the data is read and written
from a local datastore, apart from configuration items which come from
external sources. These external configuration sources govern the
operation of all the habitat commands and applications.
Refer to the habconf(5) man page for more details.
JOB DEFINITIONS
Jobs are defined in a multi columned text format, headed by the magic
string 'job 1'. Comments may appear anywhere, starting with '#' and
running to the end of the line.
Each job is defined on a single line containing 11 arguments, which in
order are:-
1. start
when to start the job, in seconds from the starting of clockwork
2. period
how often to repeat the job, in seconds
3. phase
not yet implemented
4. count
how many times the job should be run, with 0 repeating forever
5. name
name of the job
6. requester
who requested the job, by convention the email address
7. results
the route where results should be sent
8. errors
the route where errors should be sent
9. nslots
the number of slots created in the 'results' and 'errors'
routes, if applicable (applies to timestore and tablestore).
10.method
the job method
11.command
the arguments given to each method
See the habmeth(1) manpage for details of the possible methods that may
be specified and the commands that can accept.
DATA ORGANISATION
Data is stored in sequences of tabular information. All data has an
ordered independently of time, allowing multiple separate samples that
share the same time interval. This data is stored in a ringbuffer,
which allows data to grow to a certain number of samples before the
oldest are removed and their space recycled. Throughout the documenta-
tion, each collection of samples is known as a ring, and may be config-
ured to be a simple queue, where data management is left up to admin-
istrators.
To limit the amount of storage used, data in a ring can be sampled
periodically to form new summary data and stored in a new ring with a
different period. In habitat, this is known as cascading and takes
place on all the default collection rings. Several levels of cascading
can take place over several new rings, This allows summaries at differ-
ent frequencies to be collected and tuned to local requirements.
See the habmeth(1) man page for more information about the cascade
method.
DATA REPLICATION
Any ring of information can be sent to or from the repository at known
intervals, allowing a deterministic way of updating both repository and
collection agent.
This is implemented as a regular job which runs the replicate method.
Data for the method is provided by configuration parameters which can
be set and altered in the organisation. Thus the replication job does
not normally need to be altered to change the behaviour.
See the habmeth(1) man page for the replicate method and the formation
of the configuration data.
LOGGING
Clockwork and the probes that provide data, also generate information
and error messages. By convention, these are stored in the route speci-
fication ts:$hab/var/<host>.ts,log The convention for probes is to
store their errors in ts:$HAB/var/<host>.ts,e.<jobname>.
To override the logging location, use the range of elog configuration
directives, or rely on the options -d, -D, -j, which will alter the
location to stderr as a side effect. See habconf(5) for details.
Probe logging is configurable for each job in the job table.
The logging format can be customised using one of a set of configura-
tion directives (see habconf(5)). For convenience, the -e flag speci-
fies one of eight preconfigured text formats that will be sent to the
configured location:-
0 all 17 possible log variables
1 severity character & text
2 severity & text
3 severity, text, file, function & line
4 long severity, short time, short program name, file, function,
line & text
5 date time, severity, long program name, process id, file, func-
tion, line, origin, code & text
6 unix ctime, seconds since 1970, short program name, process id,
thread id, file, function, line, origin, code & text
7 severity, file, line, origin, code, text
FILES
If run from a single directory $HAB:-
$HAB/bin/clockwork
$HAB/var/<hostname>.rs, $HAB/lib/clockwork.jobs
/tmp/clockwork.run
~/.habrc, $HAB/etc/habitat.conf
If run from installed Linux locations:-
/usr/bin/habitat
/var/lib/habitat/<hostname>.rs, /usr/lib/habitat/clockwork.jobs
/var/lib/habitat/clockwork.run
~/.habrc, /etc/habitat.conf
ENVIRONMENT VARIABLES
EXAMPLES
Type the following to run clockwork in the standard way. This assumes
it is providing public data using the standard job file, storing in a
known place and using the standard network port for the data service.
clockwork
On a more secure system, you can prevent the data service from being
started
clockwork -s
Alternatively you can run it in a private mode by specifying '-j' and a
replacement job file.
clockwork -j <file>
AUTHORS
Nigel Stuckey <[email protected]>
SEE ALSO
killclock(1), ghabitat(1), habget(1), habput(1), irs(1), habedit(1),
habprobe(1), habmeth(1), habconf(5)
ghabitat
NAME
ghabitat - Gtk+ Graphical interface to Habitat suite
SYNTAX
ghabitat [-c <purl>] [-C <cfcmd>] [-e <fmt>] [-dDhsv]
DESCRIPTION
This is the standard graphical interface for Habitat, including the
ability to view repository data provided by Harvest.
When the tool starts, a check is made for the existence of the local
collection agent, clockwork. If it is not running, the user is asked
if they wish to run it and what starting behaviour they wish in the
future.
In appearance, clockwork resembles that of a file manager, with choices
on the left and visualisation on the right. If files or other data
sources have been opened before, then their re-opening is attempted by
ghabitat and will be placed under the my files node in the tree.
See DATA SOURCES section for details of the data that can be viewed,
NAVIGATION for how to interpret the data structures and VISUALISATION
for how to examine the data once displayed.
This GUI requires Xwindows to run, use other front ends or command line
tools if you do not have that facility.
OPTIONS
-c <purl>
Append user configuration data from the route <purl>, rather
than the default file ~/.habrc.
-C <cfcmd>
Append a list of configuration directives from <cfcmd>, sepa-
rated by semicolons.
-d Place ghabitat in diagnositc mode, giving an additional level of
logging and sending the text to stderr rather than the default
or configured destinations. In daemon mode, will send output to
the controlling terminal.
-D Place ghabitat in debug mode. As -d above but generating a
great deal more information, designed to be used in conjunction
with the source code. Also overrides normal outputs and will
send the text to stderr. In daemon mode, will send output to
the controlling terminal.
-e <fmt>
Change the logging output to one of eight preset alternative
formats, some showing additional information. <fmt> must be
0-7. See LOGGING below.
-h Print a help message to stdout and exit
-v Print the version to stdout and exit
-s Run in safe mode, which prevents ghabitat automatically loading
data from files or over the network from peer machines or the
repository. Use if ghabitat start up time is excessively long.
Once started, all data resourcese can be loaded manually.
DATA SOURCES
Currently, data can be obtained from four types of sources:-
Storage file
The standard local data storage file known as a ringstore, which
is a structured format using GDBM. Open it with File->Open or
^O and use the file chooser. The file will appear under my
files in the choice tree.
Repository
Centralised data automatically appears under the repository node
in the choice tree if the configuration directive is set to a
valid location. The directive is route.sqlrs.geturl which must
contain the URL of a repository output interface.
(route.sqlrs.puturl works in the opposite direction for replica-
tion.)
Network data
Data for an individual machine can be read from the repository
or a peer clockwork instance on another host. Select File->Host
or ^H, type in the hostname and pick repository or host as a
source. (Currently, host access is not fully implemented.)
Your selection will appear under my hosts in the choice tree.
Route specification
Select File->Route or ^R and type the full route specification
of the data source. This is the most generic way of addressing
in habitat, encompassing all of the styles used above and more.
Files can be removed by selecting their entry from the list brought up
with File->Close (^C).
NAVIGATION
The repository source is special, in that the hierarchical nature of the
group organisation is shown. To get to a machine, one needs to know
its organisational location and traverse it in the tree. Whilst this
aids browsing, one may wish to use the File->Host option to go directly
to a machine.
Opening the data source trees will reveal the capabilities of the data
source, which include the following:-
perf graphs
Performance data is retrieved in a time series and will display
as a chart the visualisation section
perf data
Performance data presented in a textual form, encompassing tabu-
lar time-series data, key-data values or simple list. Visuali-
sation is always in a table.
events Text scanning, pattern matching and threshold breaching func-
tionality is clustered under this node. The configuration tables
are presented here along with the events and logs that have been
generated.
logs Logs and errors from running the jobs in clockwork
replication
Logs and state of the data replication to and from the reposi-
tory
jobs The job table that clockwork follows to collect and refine data
data Contains all the data in the storage mechanism with out inter-
pretation.
Under the performance nodes will be the available data collections,
also known as rings. The names of these collections are decided when
data is inserted into the storage. For example, sending data to the
route tab:fred.ts,mydata and mounting it under ghabitat, will cause the
data to appear here as mydata.
There are conventions for the names of standard probes, but they will
only appear in a data store if their collection is configured in the
job table (usually just uncommenting it: see clockwork(1)):-
sys System data, such as cpu statistics and memory use. Labelled as
system in choice tree
io Disk statistics, such as read/write rates and performance lev-
els. Labelled as storage in the choice tree
net Network statistics, such as packets per second. Labelled as
network in the choice tree
ps Process table. This can contain a significant amount of data
over time, so generally only the most significant or useful pro-
cesses may be included. This is dependent on the configuration
of the ps probe. Labelled as processes in the choice tree
names A set of name-value pairs relating to the configuration of the
operating system. Generally captured at start up only.
The final set of nodes below the ring names are a set of time scales by
which to examine the data. These dictate how much data is extracted
from the data source and generally the speed at which the data will be
visualised. These are preset to useful values, commonly 5 minutes, 1
hour, 4 hours, 1 day, 7 days, 1 month, 3 months, 1 year, 3 years, etc.
VISUALISATION
The right hand section of the window is used for visualisation. Its
major uses are for charting and displaying tables.
When charting, the section is divided into several parts. The greatest
is used for the graph itself, with other areas being used for curve
selection, zooming and data scaling. If the data is multi-instance,
such as with multiple disks, then a further area is added to control
the number of instance graphs being displayed.
The standard sets of data, such as sys and io have default curves that
are displayed when the graph is first drawn. The list of curves down
the right hand side are buttons used to draw or remove data on the
graph. When drawn, the button changes colour to that of of the curve
displayed.
Whilst the largest amount of data displayed is selected from the choice
tree, it is possible to 'zoom-in' to particular times very easily using
the graph. There are two methods: either drag the mouse of the area of
interest, creating a rectangle and click the left button inside or use
the x and y axis zoom buttons from the Zoom & Scale area. The display
shows the enlarged view and changes the scale the x & y rulers. The
time ruler is changes mode to show the most useful feedback of time at
that scale. To move back and forth along time, move the horizontal
scrollbar. To zoom out, either click the right mouse button over the
graph or use the zoom-out button in the Zoom & Scale area.
It is possible to alter the scale and offset of the curves by clicking
on the additional fields button in the Zoom & Scale area. This will
create addition scale and offset controls next to each curve button.
The values relate to the formula y = mx + c, where the offset is c and
the scale is m. Moving the scale changes the magnitude of the curve,
whereas the offset changes the point at which the curve originates.
Using these tools, simple parity can be gained between two curves that
you wish to superimpose on the same chart but do not share the same y
scale.
MENU
The File menu adds and removes file and other data sources to the
choice tree. It also contains import and export routines to convert
between native datastores and plain text, such as csv and tsv files.
The View menu controls the display and refresh of choice and visualisa-
tion. It also give the ability to save or send data being displayed to
e-mail, applications or a file.
The Collect menu controls data collection, if you own the collection
process.
The Graph menu changes the appearance of the chart and is only dis-
played when the graph appears.
Finally, the Help menu gives access to spot help, documentation and
links to the system garden web site for product information. Most help
menu items need a common browser on the users path to show help infor-
mation.
LOGGING
Ghabitat generates information and error messages. By default, errors
are captured internally and can be displayed in the visualisation area
by clicking on the logs node under this client.
Also available in this area are the log routes, which shows the how
information of different severity is dealt with and configuration,
which shows the values of all the current configuration directives in
effect.
See habconf(5) for more information.
FILES
Locations alter depending on how the application is installed.
For the habitat configuration
~/.habrc
$HAB/etc/habitat.conf or /etc/habitat.conf
For graphical appearance: fonts, colours, styles, etc
$HAB/lib/ghabitat.rc or /usr/lib/habitat/ghabitat.rc
For the help information
$HAB/lib/help/ or /usr/lib/habitat/help/
ENVIRONMENT VARIABLES
DISPLAY
The X-Windows display to use
PATH Used to locate a browser to display help information. Typical
browsers looked for are Mozilla, Netscape, Konqueror, Opera,
Chimera
HOME User's home directory
AUTHORS
Nigel Stuckey <[email protected]>
SEE ALSO
clockwork(1), killclock(1), habget(1), habput(1), irs(1), habedit(1),
habprobe(1), habmeth(1), habconf(5)
habget
NAME
habget - Send habitat data to stdout
SYNTAX
habget [-c <purl>] [-C <cfcmd>] [-e <fmt>] [-dDhv] [-E] <route>
DESCRIPTION
Open <route> using habitat's route addressing and send the data to std-
out.
See clockwork(1) for an explanation of the route syntax
OPTIONS
-c <purl>
Append user configuration data from the route <purl>, rather
than the default file ~/.habrc.
-C <cfcmd>
Append a list of configuration directives from <cfcmd>, sepa-
rated by semicolons.
-d Place ghabitat in diagnostic mode, giving an additional level of
logging and sending the text to stderr rather than the default
or configured destinations. In daemon mode, will send output to
the controlling terminal.
-D Place ghabitat in debug mode. As -d above but generating a
great deal more information, designed to be used in conjunction
with the source code. Also overrides normal outputs and will
send the text to stderr. In daemon mode, will send output to
the controlling terminal.
-e <fmt>
Change the logging output to one of eight preset alternative
formats, some showing additional information. <fmt> must be
0-7. See LOGGING below.
-h Print a help message to stdout and exit
-v Print the version number to stdout and exit
-E Escape characters in data that would otherwise be unprintable
EXAMPLES
To output the job table from an established datastore file used for
public data collection. This uses the ringstore driver.
habget rs:var/myhost.rs,clockwork,0
To get the most recent data sample from the 60 second sys ring from the
same datastore as above.
habget rs:var/myhost.rs,sys,60
To find errors that may have been generated by clockwork.
habget rs:var/myhost.rs,log,0
habput
NAME
habput - Store habitat data from stdin
SYNTAX
habput [-s <nslots> -t <desc>] [-c <purl>] [-C <cfcmd>] [-e <fmt>]
[-dDhv] <route>
DESCRIPTION
Open <route> using habitat's route addressing and send data from stdin
to the route.
See clockwork(1) for an explanation of the route syntax
OPTIONS
-c <purl>
Append user configuration data from the route <purl>, rather
than the default file ~/.habrc.
-C <cfcmd>
Append a list of configuration directives from <cfcmd>, sepa-
rated by semicolons.
-d Place ghabitat in diagnostic mode, giving an additional level of
logging and sending the text to stderr rather than the default
or configured destinations. In daemon mode, will send output to
the controlling terminal.
-D Place ghabitat in debug mode. As -d above but generating a
great deal more information, designed to be used in conjunction
with the source code. Also overrides normal outputs and will
send the text to stderr. In daemon mode, will send output to
the controlling terminal.
-e <fmt>
Change the logging output to one of eight preset alternative
formats, some showing additional information. <fmt> must be
0-7. See LOGGING below.
-h Print a help message to stdout and exit
-v Print the version to stdout and exit
-s <nslots>
Number of slots for creating ringed routes (default 1000);
<nslots> of 0 gives a queue behaviour where the oldest data is
not lost
-t <desc>
text description for creating ringed routes
EXAMPLES
To append a sample of tabular data to a table store, use a tablestore
driver. This will create a ring which can store 1,000 slots of data.
habput tab:var/myfile.ts,myring
To save the same data, but limit the ring to just the most recent 10
slots and give the ring a description
habput -s 10 -t "my description" tab:var/myfile.ts,myring
The same data, stored to the same location, but with an unlimited his-
tory (technically a queue). To make the ring readable in ghabitat with
current conventions, we store with the prefix '.r'
habput -s 0 -t "my description" tab:var/myfile.ts,r.myring
To save an error record, use a timestore driver
habput -s 100 -t "my logs" ts:var/myfile.ts,mylogs
AUTHORS
Nigel Stuckey <[email protected]>
SEE ALSO
clockwork(1), killclock(1), ghabitat(1), habget(1), irs(1), habedit(1),
habprobe(1), habmeth(1), habconf(5)
killclock
NAME
killclock - Stops clockwork, Habitat's collection agent
SYNTAX
killclock
DESCRIPTION
Stops the public instance of clockwork running on the local machine.
This shell script locates the lock file for clockwork, which is the
collection agent for the Habitat suite. It prints the process id, own-
ing user, controlling terminal and start time of the daemon, before
sending it a SIGTERM.
No check is made that the clockwork process has terminated before this
script ends.
Private instances of clockwork (started with -j option) can not be
stopped by this method, as they do not register in a lock file.
Instead, they should be controlled by conventional process control
methods.
FILES
/tmp/clockwork.run
/var/run/clockwork.run
EXAMPLES
Typing the following:-
killclock
will result in a display similar to below and the termination of the
clockwork daemon.
Stopping pid 2781, user nigel and started on /dev/pts/2 at 25-May-04
08:08:55 AM
AUTHORS
Nigel Stuckey <[email protected]>
SEE ALSO
clockwork(1), ghabitat(1), habget(1), habput(1), irs(1), habedit(1),
habprobe(1), habmeth(1), habconf(5)
Collected Data
The tables below shows the data that is collected by the standard probes in habitat, one table per operating system. It may not be up to date, so always check with the application itself.
Linux Data
|
Probe |
Measure |
Description |
|
system (sys) |
load1 |
1 minute load average |
|
load5 |
5 minute load average |
|
|
load15 |
15 minute load average |
|
|
runque |
number of runnable processes |
|
|
nprocs |
number of processes |
|
|
lastproc |
id of last process run |
|
|
mem_tot |
total memory (kB) |
|
|
mem_used |
memory used (kB) |
|
|
mem_free |
memory free (kB) |
|
|
mem_shared |
used memory shared (kB) |
|
|
mem_buf |
buffer memory (kB) |
|
|
mem_cache |
cache memory (kB) |
|
|
swap_tot |
total swap space (kB) |
|
|
swap_used |
swap space used (kB) |
|
|
swap_free |
swap space free (kB) |
|
|
uptime |
seconds that the system has been up |
|
|
idletime |
seconds that system has been idle |
|
|
%user |
% time cpu was in user space |
|
|
%nice |
% time cpu was at nice priority in user space |
|
|
%system |
% time cpu spent in kernel |
|
|
%idle |
% time cpu was idle |
|
|
pagein |
pages paged in per second |
|
|
pageout |
pages paged out per second |
|
|
swapin |
pages swapped in per second |
|
|
swapout |
pages swapped out per second |
|
|
interrupts |
hardware interrupts per second |
|
|
contextsw |
context switches per second |
|
|
forks |
process forks per second |
|
|
storage (io) |
id |
mount or device identifier |
|
device |
device name |
|
|
mount |
mount point |
|
|
fstype |
filesystem type |
|
|
size |
size of filesystem or device (MBytes) |
|
|
used |
space used on device (MBytes) |
|
|
reserved |
reserved space in filesystem (KBytes) |
|
|
%used |
% used on device |
|
|
kread |
volume of data read (KB/s) |
|
|
kwritten |
volume of data written (KB/s) |
|
|
rios |
number of read operations per second |
|
|
wios |
number of write operations per second |
|
|
read_svc_t |
average read service time (ms) |
|
|
write_svc_t |
average write service time (ms) |
|
|
network (net) |
device |
device name |
|
rx_bytes |
bytes received |
|
|
rx_pkts |
packets received |
|
|
rx_errs |
receive errors |
|
|
rx_drop |
receive dropped packets |
|
|
rx_fifo |
received fifo |
|
|
rx_frame |
receive frames |
|
|
rx_comp |
receive compressed |
|
|
rx_mcast |
received multicast |
|
|
tx_bytes |
bytes transmitted |
|
|
tx_pkts |
packets transmitted |
|
|
tx_errs |
transmit errors |
|
|
tx_drop |
transmit dropped packets |
|
|
tx_fifo |
transmit fifo |
|
|
tx_colls |
transmit collisions |
|
|
tx_carrier |
transmit carriers |
|
|
tx_comp |
transmit compressed |
|
|
uptime (up) |
uptime |
uptime in secs |
|
boot |
time of boot in secs from epoch |
|
|
suspend |
secs suspended |
|
|
vendor |
vendor name |
|
|
model |
model name |
|
|
nproc |
number of processors |
|
|
mhz |
processor clock speed |
|
|
cache |
size of cache in kb |
|
|
fpu |
floating point unit available |
|
|
downtime |
lastup |
time last alive in seconds from epoch |
|
boot |
time of boot in secs from epoch |
|
|
downtime |
secs unavailable |
|
|
processes (ps) |
pid |
process id |
|
ppid |
process id of parent |
|
|
pidglead |
process id of process group leader |
|
|
sid |
session id |
|
|
uid |
real user id |
|
|
pwname |
name of real user |
|
|
euid |
effective user id |
|
|
epwname |
name of effective user |
|
|
gid |
real group id |
|
|
egid |
effective group id |
|
|
size |
size of process image in Kb |
|
|
rss |
resident set size in Kb |
|
|
flag |
process flags (system dependent) |
|
|
nlwp |
number of lightweight processes within this process |
|
|
tty |
controlling tty device |
|
|
%cpu |
% of recent cpu time |
|
|
%mem |
% of system memory |
|
|
start |
process start time from epoc |
|
|
time |
total cpu time for this process |
|
|
childtime |
total cpu time for reaped child processes |
|
|
nice |
nice level for cpu scheduling |
|
|
syscall |
system call number (if in kernel) |
|
|
pri |
priority (high value=high priority) |
|
|
wchan |
wait address for sleeping process |
|
|
wstat |
if zombie the wait() status |
|
|
cmd |
command/name of exec'd file |
|
|
args |
full command string |
|
|
user_t |
user level cpu time |
|
|
sys_t |
sys call cpu time |
|
|
otrap_t |
other system trap cpu time |
|
|
textfault_t |
text page fault sleep time |
|
|
datafault_t |
data page fault sleep time |
|
|
kernelfault_t |
kernel page fault sleep time |
|
|
lockwait_t |
user lock wait sleep time |
|
|
osleep_t |
all other sleep time |
|
|
waitcpu_t |
wait-cpu (latency) time |
|
|
stop_t |
stopped time |
|
|
minfaults |
minor page faults |
|
|
majfaults |
major page faults |
|
|
nswaps |
number of swaps |
|
|
inblock |
input blocks |
|
|
outblock |
output blocks |
|
|
msgsnd |
messages sent |
|
|
msgrcv |
messages received |
|
|
sigs |
signals received |
|
|
volctx |
voluntary context switches |
|
|
involctx |
involuntary context switches |
|
|
syscalls |
system calls |
|
|
chario |
characters read and written |
|
|
pendsig |
set of process pending signals |
|
|
heap_vaddr |
virtual address of process heap |
|
|
heap_size |
size of process heap in bytes |
|
|
stack_vaddr |
virtual address of process stack |
|
|
stack_size |
size of process stack in bytes |
|
|
hardware |
name |
device name |
|
hard |
interrupts from hardware device |
|
|
soft |
interrupts self induced by system |
|
|
watchdog |
interrupts from a periodic timer |
|
|
spurious |
interrupts for unknown reason |
|
|
multisvc |
multiple servicing during single interrupt |
|
|
system |
name |
name |
|
vname |
value name |
|
|
value |
value of symbol |
Solaris Data
|
Probe |
Measure |
Description |
|
system (sys) |
updates |
|
|
runque |
+= num runnable procs |
|
|
runocc |
++ if num runnable procs > 0 |
|
|
swpque |
+= num swapped procs |
|
|
swpocc |
++ if num swapped procs > 0 |
|
|
waiting |
+= jobs waiting for I/O |
|
|
freemem |
+= freemem in pages |
|
|
swap_resv |
+= reserved swap in pages |
|
|
swap_alloc |
+= allocated swap in pages |
|
|
swap_avail |
+= unreserved swap in pages |
|
|
swap_free |
+= unallocated swap in pages |
|
|
%idle |
time cpu was idle |
|
|
%wait |
time cpu was idle waiting for IO |
|
|
%user |
time cpu was in user space |
|
|
%system |
time cpu was in kernel space |
|
|
wait_io |
time cpu was idle waiting for IO |
|
|
wait_swap |
time cpu was idle waiting for swap |
|
|
wait_pio |
time cpu was idle waiting for programmed I/O |
|
|
bread |
physical block reads |
|
|
bwrite |
physical block writes (sync+async) |
|
|
lread |
logical block reads |
|
|
lwrite |
logical block writes |
|
|
phread |
raw I/O reads |
|
|
phwrite |
raw I/O writes |
|
|
pswitch |
context switches |
|
|
trap |
traps |
|
|
intr |
device interrupts |
|
|
syscall |
system calls |
|
|
sysread |
read() + readv() system calls |
|
|
syswrite |
write() + writev() system calls |
|
|
sysfork |
forks |
|
|
sysvfork |
vforks |
|
|
sysexec |
execs |
|
|
readch |
bytes read by rdwr() |
|
|
writech |
bytes written by rdwr() |
|
|
rawch |
terminal input characters |
|
|
canch |
chars handled in canonical mode |
|
|
outch |
terminal output characters |
|
|
msg |
msg count (msgrcv()+msgsnd() calls) |
|
|
sema |
semaphore ops count (semop() calls) |
|
|
namei |
pathname lookups |
|
|
ufsiget |
ufs_iget() calls |
|
|
ufsdirblk |
directory blocks read |
|
|
ufsipage |
inodes taken with attached pages |
|
|
ufsinopage |
inodes taked with no attached pages |
|
|
inodeovf |
inode table overflows |
|
|
fileovf |
file table overflows |
|
|
procovf |
proc table overflows |
|
|
intrthread |
interrupts as threads (below clock) |
|
|
intrblk |
intrs blkd/prempted/released (switch) |
|
|
idlethread |
times idle thread scheduled |
|
|
inv_swtch |
involuntary context switches |
|
|
nthreads |
thread_create()s |
|
|
cpumigrate |
cpu migrations by threads |
|
|
xcalls |
xcalls to other cpus |
|
|
mutex_adenters |
failed mutex enters (adaptive) |
|
|
rw_rdfails |
rw reader failures |
|
|
rw_wrfails |
rw writer failures |
|
|
modload |
times loadable module loaded |
|
|
modunload |
times loadable module unloaded |
|
|
bawrite |
physical block writes (async) |
|
|
iowait |
procs waiting for block I/O |
|
|
pgrec |
page reclaims (includes pageout) |
|
|
pgfrec |
page reclaims from free list |
|
|
pgin |
pageins |
|
|
pgpgin |
pages paged in |
|
|
pgout |
pageouts |
|
|
pgpgout |
pages paged out |
|
|
swapin |
swapins |
|
|
pgswapin |
pages swapped in |
|
|
swapout |
swapouts |
|
|
pgswapout |
pages swapped out |
|
|
zfod |
pages zero filled on demand |
|
|
dfree |
pages freed by daemon or auto |
|
|
scan |
pages examined by pageout daemon |
|
|
rev |
revolutions of the page daemon hand |
|
|
hat_fault |
minor page faults via hat_fault() |
|
|
as_fault |
minor page faults via as_fault() |
|
|
maj_fault |
major page faults |
|
|
cow_fault |
copy-on-write faults |
|
|
prot_fault |
protection faults |
|
|
softlock |
faults due to software locking req |
|
|
kernel_asflt |
as_fault()s in kernel addr space |
|
|
pgrrun |
times pager scheduled |
|
|
nc_hits |
hits that we can really use |
|
|
nc_misses |
cache misses |
|
|
nc_enters |
number of enters done |
|
|
nc_dblenters |
num of enters when already cached |
|
|
nc_longenter |
long names tried to enter |
|
|
nc_longlook |
long names tried to look up |
|
|
nc_mvtofront |
entry moved to front of hash chain |
|
|
nc_purges |
number of purges of cache |
|
|
flush_ctx |
num of context flushes |
|
|
flush_segment |
num of segment flushes |
|
|
flush_page |
num of complete page flushes |
|
|
flush_partial |
num of partial page flushes |
|
|
flush_usr |
num of non-supervisor flushes |
|
|
flush_region |
num of region flushes |
|
|
var_buf |
num of I/O buffers |
|
|
var_call |
num of callout (timeout) entries |
|
|
var_proc |
max processes system wide |
|
|
var_maxupttl |
max user processes system wide |
|
|
var_nglobpris |
num of global scheduled priorities configured |
|
|
var_maxsyspri |
max global priorities used by system class |
|
|
var_clist |
num of clists allocated |
|
|
var_maxup |
max number of processes per user |
|
|
var_hbuf |
num of hash buffers to allocate |
|
|
var_hmask |
hash mask for buffers |
|
|
var_pbuf |
num of physical I/O buffers |
|
|
var_sptmap |
size of sys virt space alloc map |
|
|
var_maxpmem |
max physical memory to use in pages (if 0 use all available) |
|
|
var_autoup |
min secs before a delayed-write buffer can be flushed |
|
|
var_bufhwm |
high water mrk of buf cache in KB |
|
|
var_xsdsegs |
num of XENIX shared data segs |
|
|
var_xsdslots |
num of slots in xsdtab[] per segmt |
|
|
flock_reccnt |
num of records currently in use |
|
|
flock_rectot |
num of records used since boot |
|
|
processes (ps) |
pid |
process id |
|
ppid |
process id of parent |
|
|
pidglead |
process id of process group leader |
|
|
sid |
session id |
|
|
uid |
real user id |
|
|
pwname |
name of real user |
|
|
euid |
effective user id |
|
|
epwname |
name of effective user |
|
|
gid |
real group id |
|
|
egid |
effective group id |
|
|
size |
size of process image in Kb |
|
|
rss |
resident set size in Kb |
|
|
flag |
process flags (system dependent) |
|
|
nlwp |
number of lightweight processes within this process |
|
|
tty |
controlling tty device |
|
|
%cpu |
% of recent cpu time |
|
|
%mem |
% of system memory |
|
|
start |
process start time from epoc |
|
|
time |
total cpu time for this process |
|
|
childtime |
total cpu time for reaped child processes |
|
|
nice |
nice level for scheduling |
|
|
syscall |
system call number (if in kernel) |
|
|
pri |
priority (high value=high priority) |
|
|
wchan |
wait address for sleeping process |
|
|
wstat |
if zombie the wait() status |
|
|
cmd |
command/name of exec'd file |
|
|
args |
full command string |
|
|
user_t |
user level cpu time |
|
|
sys_t |
sys call cpu time |
|
|
otrap_t |
other system trap cpu time |
|
|
textfault_t |
text page fault sleep time |
|
|
datafault_t |
data page fault sleep time |
|
|
kernelfault_t |
kernel page fault sleep time |
|
|
lockwait_t |
user lock wait sleep time |
|
|
osleep_t |
all other sleep time |
|
|
waitcpu_t |
wait-cpu (latency) time |
|
|
stop_t |
stopped time |
|
|
minfaults |
minor page faults |
|
|
majfaults |
major page faults |
|
|
nswaps |
number of swaps |
|
|
inblock |
input blocks |
|
|
outblock |
output blocks |
|
|
msgsnd |
messages sent |
|
|
msgrcv |
messages received |
|
|
sigs |
signals received |
|
|
volctx |
voluntary context switches |
|
|
involctx |
involuntary context switches |
|
|
syscalls |
system calls |
|
|
chario |
characters read and written |
|
|
pendsig |
set of process pending signals |
|
|
heap_vaddr |
virtual address of process heap |
|
|
heap_size |
size of process heap bytes |
|
|
stack_vaddr |
virtual address of process stack |
|
|
stack_size |
size of process stack bytes |
|
|
storage (io) |
device |
device name |
|
nread |
number of bytes read |
|
|
nwritten |
number of bytes written |
|
|
reads |
number of read operations |
|
|
writes |
number of write operations |
|
|
wait_t |
cumulative wait (pre-service) time |
|
|
wait_len_t |
cumulative wait length*time product |
|
|
run_t |
cumulative run (service) time |
|
|
run_len_t |
cumulative run length*time product |
|
|
wait_cnt |
wait count |
|
|
run_cnt |
run count |
|
|
System |
name |
name |
|
vname |
value name |
|
|
value |
value |
|
|
system timers |
kname |
timer name |
|
name |
event name |
|
|
nevents |
number of events |
|
|
elapsed_t |
cumulative elapsed time |
|
|
min_t |
shortest event duration |
|
|
max_t |
longest event duration |
|
|
start_t |
previous event start time |
|
|
stop_t |
previous event stop time |
|
|
uptime (up) |
uptime |
uptime in secs |
|
boot |
time of boot in secs from epoch |
|
|
suspend |
secs suspended |
|
|
vendor |
vendor name |
|
|
model |
model name |
|
|
nproc |
number of processors |
|
|
mhz |
processor clock speed |
|
|
cache |
size of cache in kb |
|
|
fpu |
floating point unit available |
|
|
down- |
lastup |
time last alive in secs from epoch |
|
boot |
time of boot in secs from epoch |
|
|
downtime |
secs unavailable |
|
|
hardware
|
name |
device name |
|
hard |
interrupt from hardware device |
|
|
soft |
interrupt self induced by system |
|
|
watchdog |
interrupt from periodic timer |
|
|
spurious |
interrupt for unknown reason |
|
|
multisvc |
multiple servicing during single interrupt |
Fat Headed Array Format
The Fat Headed Array is a table of information designed for transportation between systems and external representation. Habitat uses FHAs when reading clockwork's central store and for I/O work with harvest. It is also used when loading data into harvest's repository when linking with other systems.
There are three parts to the data in the following order:
Column names: tab separated attribute names that must be in line 1
Info Rows: zero or more lines of meta information for each attribute. Each meta record takes one line, separating its fields with tabs which must be in the same order as the attribute names. Each info row is named with a trailing supplementary field, such that these rows have one more column than the data or column name rows. Info rows are terminated with a row which must start with two dashes '--'.
One or more data rows to follow the column names and info rows.
The following is an example of a FHA.
To represent an empty value, two quotes should be used (“”). Occasionally, this may also be represented as a single dash.
To represent a value that contains tab characters (\t), the value should be contains in quotes (eg “embedded \t tab“).
Column names may only contain characters accepted by SQL database servers to ensure compatibility. This is generally accepted as the range [A-Za-z_]. See the info row name below for greater expression.
In addition to pure character formatting, ghabitat the graphical client, also understands certain named info rows.
info – the text in the row is used as informational help in the client. This can be seen when hovering the mouse over a column name in a table or a curve's button when displaying charts. The information is contained in graphical 'pop-ups' or 'tool tips'.
max – Optional value which, if present, sets the maximum expected value for an attribute. This helps in making charts more understandable.
type – the data type of the column. In version 1, the data types are relatively simple:-
i32 – 32-bit signed integer
u32 – 32-bit unsigned integer
i64 – 64 bit signed integer
u64 – 64bit unsigned integer
nano – nano second precision when used for timers. Currently also used for floating point values with more restrictive accuracy
str – string value
key – The column that is the primary key of the table contains a 1, all the other values contain no value (“”). May be expanded to show secondary or tertiary keys in later versions.
name – The unrestricted full name of the column, if it is not possible to express it in the column name. If blank, the column name is used as the attribute's label. This is used to include punctuation characters such as '-' or '%' in the label as they are disallowed by the SQL naming standard but can be very useful for compact expression.
Job Table Format
Clockwork reads a job table and uses the information to establish repeating and timed jobs. It is similar to the Unix scheduler cron, but with greater flexibility.
When first run, clockwork boot straps an initial version of its jobs from the file lib/clockwork.jobs. The resulting table is stored in the ringstore location var/<hostname>.rs,jobs,0. Subsequent runs of clockwork will use this table, so any amendments should be made using habedit on the ringstore route.
Clockwork may also be started with an alternate job table by using the the -j switch to clockwork. In this mode, clockwork runs a private data collector with out starting a network service for the whole machine.
Jobs are defined in a multi columned text format, headed by the magic string 'job 1'. Comments may appear anywhere, starting with '#' and running to the end of the line. Each job is defined on a single line containing 11 arguments, which in order are:-
start – when to start the job, in seconds from the starting of clockwork
period – how often to repeat the job, in seconds
phase – not yet implemented
count – how many times the job should be run, with 0 repeating forever
name – name of the job
requester – who requested the job, by convention the email address
results – the route where results should be sent
errors – the route where errors should be sent
nslots – the number of slots created in the 'results' and 'errors' routes, if applicable (applies to ringstore and SQL ringstore).
method – the job method
command – the arguments given to each method
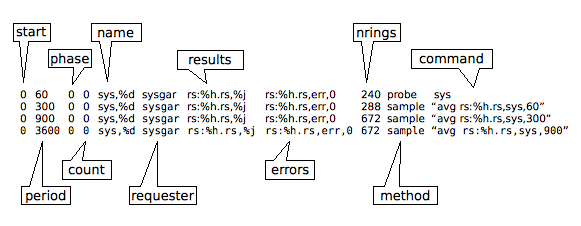
Part
of a job table taken from the default file lib/clockwork.jobs
is printed below. The top line runs the sys
probe every 60 seconds, gathering system data (which becomes the
system
node in the choice tree). The
remaining lines use the collected high frequency data and transform
it to lower frequencies using an averaging process, running every
five minutes, fifteen minutes and one month (300, 900 and 3600
seconds).
The job running every 300 seconds creates a storage ring with 288 entries, allowing a full day's data at five minute intervals to be collected. The other jobs collect seven days at 15 minutes and one month at hourly intervals.
The methods are probe which is given the command sys, and sample which has the command avg and the route to sample as its argument. These methods are available on the command line using habmeth. The probe data is similarly available using the command habprobe.
Note that special tokens are used which expand when clockwork is running. These are %d for the ring's duration and %h for the hostname. Other tokens are available which are explored in the Administration manual.
Pattern Matching Table Format
The pattern matching table is user configurable, using the processing mechanism is described earlier in this document.
The pattern-matching table, which defines the bahaviour has the following columns:
pattern – the regular expression to look for as a pattern, which should normally match a single line. Each match is considered an event.
embargo time – number of seconds that must elapse after the first event before another event may be raised of the same pattern from the same route.
embargo count – maximum number of identical pattern matches that can take place before another event is raised for that pattern and route.
severity – importance of the event. One of: fatal, error, warning, info, diag, debug
action method – event's execution method
action arguments – method specific arguments
action message – text message to describe the event. It may contain special tokens of the form %<char> that describe other information about the event.
When the event is detected and is not subject to embargo, then an event is raised. A text message is prepared which is turned into an instruction using the action method and arguments. Then, it is appended to the event ring for execution (see below).
Watched Sources Table Format
The watched sources table defines a set of routes associated with a identifier. A watching job then ties together a set of sources with a set of patterns and executes them periodically. When the watching job starts, it checks all the routes defined in this table for changes in size. Those that have changed will be checked for pattern matches (see the details above).
The format of the table is simple: one entry per line, with each being a valid route format.
Event Table Format
The event table is filled from the activities of pattern matching and threshold detection. When there is a match not covered by an embargo, an event will be raised, which is a instruction to execute a method supported by the habitat job environment. The instructions are queued as separate sequences in the event ring, which is stored in the system ringstore.
The table format is simple:-
method – execution method as supported by the habitat job environment.
command – command to give to method
arguments – command arguments, which may contain spaces. The '%' character must be escaped if it is to be used in an argument (see below)
stdin – input text to the method, which must be introduced with '%' to separate it from the argument. Successive % characters represent new lines. To actually print %, escape it with backslash (\%).
When an event has been completed, the next sequence to be processed is stored in a state table. The event ring is a finite length, so old events will be removed automatically over time.